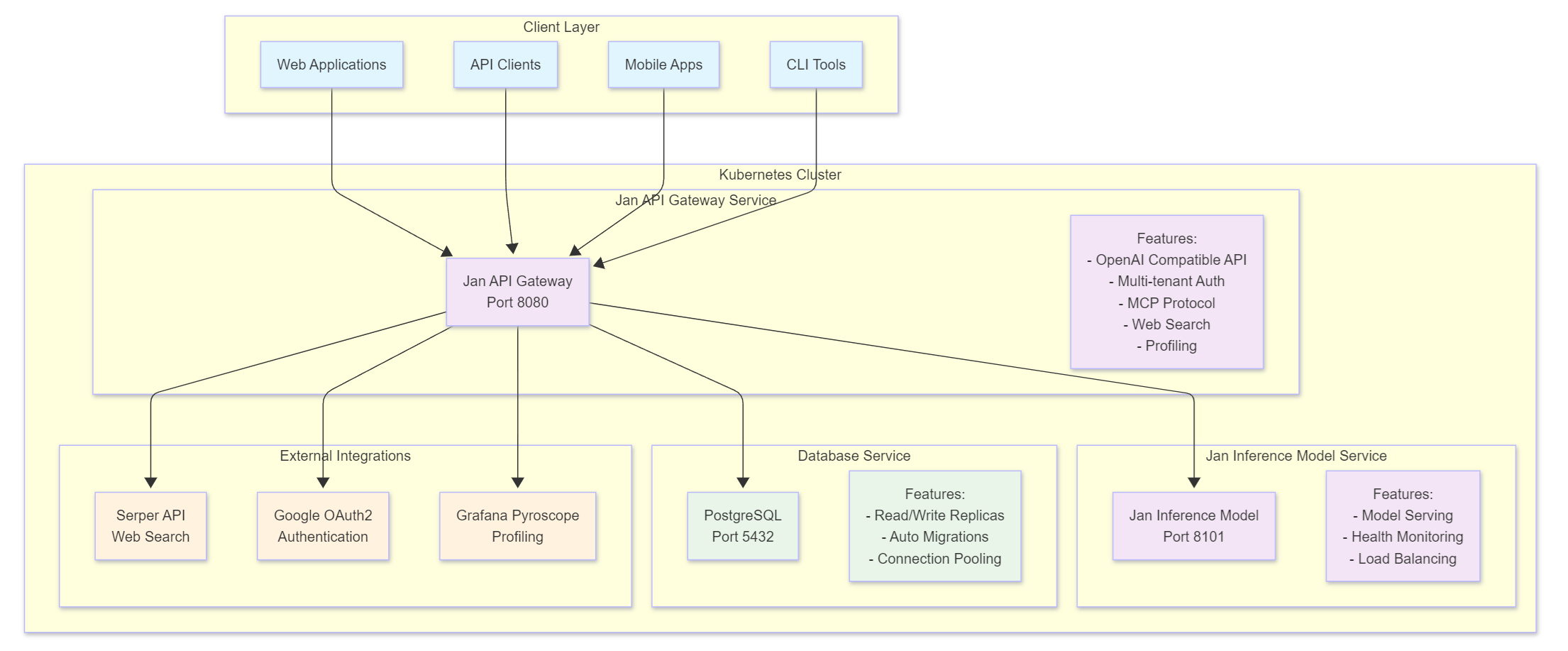
System Overview
Jan Server is a comprehensive self-hosted AI server platform that provides OpenAI-compatible APIs, multi-tenant organization management, and AI model inference capabilities. Jan Server enables organizations to deploy their own private AI infrastructure with full control over data, models, and access.
Jan Server is a Kubernetes-native platform consisting of multiple microservices that work together to provide a complete AI infrastructure solution. It offers:
Key Features
- OpenAI-Compatible API: Full compatibility with OpenAI's chat completion API
- Multi-Tenant Architecture: Organization and project-based access control
- AI Model Inference: Scalable model serving with health monitoring
- Database Management: PostgreSQL with read/write replicas
- Authentication & Authorization: JWT + Google OAuth2 integration
- API Key Management: Secure API key generation and management
- Model Context Protocol (MCP): Support for external tools and resources
- Web Search Integration: Serper API integration for web search capabilities
- Monitoring & Profiling: Built-in performance monitoring and health checks
Business Domain Architecture
Core Domain Models
User Management
- Users: Support for both regular users and guest users with email-based authentication
- Organizations: Multi-tenant organizations with owner/member roles and hierarchical access
- Projects: Project-based resource isolation within organizations with member management
- Invites: Email-based invitation system for organization and project membership
Authentication & Authorization
- API Keys: Multiple types (admin, project, organization, service, ephemeral) with scoped permissions
- JWT Tokens: Stateless authentication with Google OAuth2 integration
- Role-Based Access: Hierarchical permissions from organization owners to project members
Conversation Management
- Conversations: Persistent chat sessions with metadata and privacy controls
- Items: Rich conversation items supporting messages, function calls, and reasoning content
- Content Types: Support for text, images, files, and multimodal content with annotations
- Status Tracking: Real-time status management (pending, in_progress, completed, failed, cancelled)
Response Management
- Responses: Comprehensive tracking of AI model interactions with full parameter logging
- Streaming: Real-time streaming with Server-Sent Events and chunked transfer encoding
- Usage Statistics: Token usage tracking and performance metrics
- Error Handling: Detailed error tracking with unique error codes
External Integrations
- Jan Inference Service: Primary AI model inference backend with health monitoring
- Serper API: Web search capabilities via MCP with search and webpage fetching
- SMTP: Email notifications for invitations and system alerts
- Model Registry: Dynamic model discovery and health checking
Data Flow Architecture
- Request Processing: HTTP requests → Authentication → Authorization → Business Logic
- AI Inference: Request → Jan Inference Service → Streaming Response → Database Storage
- MCP Integration: JSON-RPC 2.0 → Tool Execution → External APIs → Response Streaming
- Health Monitoring: Cron Jobs → Service Discovery → Model Registry Updates
- Database Operations: Read/Write Replicas → Transaction Management → Automatic Migrations
Components
Jan API Gateway
The core API service that provides OpenAI-compatible endpoints and manages all client interactions.
Key Features:
- OpenAI-compatible chat completion API with streaming support
- Multi-tenant organization and project management
- JWT-based authentication with Google OAuth2 integration
- API key management at organization and project levels
- Model Context Protocol (MCP) support for external tools
- Web search integration via Serper API
- Comprehensive monitoring and profiling capabilities
- Database transaction management with automatic rollback
Technology Stack:
- Backend: Go 1.24.6
- Web Framework: Gin v1.10.1
- Database: PostgreSQL with GORM v1.30.1
- Database Features:
- Read/Write Replicas with GORM dbresolver
- Automatic migrations with Atlas
- Generated query interfaces with GORM Gen
- Authentication: JWT v5.3.0 + Google OAuth2 v3.15.0
- API Documentation: Swagger/OpenAPI v1.16.6
- Streaming: Server-Sent Events (SSE) with chunked transfer
- Dependency Injection: Google Wire v0.6.0
- Logging: Logrus v1.9.3 with structured logging
- HTTP Client: Resty v3.0.0-beta.3
- Profiling:
- Built-in pprof endpoints
- Grafana Pyroscope Go integration v0.1.8
- Scheduling: Crontab v1.2.0 for health checks
- MCP Protocol: MCP-Go v0.37.0 for Model Context Protocol
- External Integrations:
- Jan Inference Service
- Serper API (Web Search)
- Google OAuth2
- Development Tools:
- Atlas for database migrations
- GORM Gen for code generation
- Swagger for API documentation
Project Structure:
jan-api-gateway/├── application/ # Go application code├── docker/ # Docker configuration└── README.md # Service-specific documentation
Jan Inference Model
The AI model serving service that handles model inference requests.
Key Features:
- Scalable model serving infrastructure
- Health monitoring and automatic failover
- Load balancing across multiple model instances
- Integration with various AI model backends
Technology Stack:
- Python-based model serving
- Docker containerization
- Kubernetes-native deployment
Project Structure:
jan-inference-model/├── application/ # Python application code└── Dockerfile # Container configuration
PostgreSQL Database
The persistent data storage layer with enterprise-grade features.
Key Features:
- Read/write replica support for high availability
- Automatic schema migrations with Atlas
- Connection pooling and optimization
- Transaction management with rollback support
Schema:
- User accounts and authentication
- Conversation history and management
- Project and organization management
- API keys and access control
- Response tracking and metadata
Data Flow
Request Processing
- Client Request: HTTP request to API gateway on port 8080
- Authentication: JWT token validation or OAuth2 flow
- Request Routing: Gateway routes to appropriate handler
- Database Operations: GORM queries for user data/state
- Inference Call: HTTP request to model service on port 8101
- Response Assembly: Gateway combines results and returns to client
Authentication Flow
JWT Authentication:
- User provides credentials
- Gateway validates against database
- JWT token issued with HMAC-SHA256 signing
- Subsequent requests include JWT in Authorization header
OAuth2 Flow:
- Client redirected to Google OAuth2
- Authorization code returned to redirect URL
- Gateway exchanges code for access token
- User profile retrieved from Google
- Local JWT token issued
Deployment Architecture
Kubernetes Resources
Deployments:
jan-api-gateway: Single replica Go applicationjan-inference-model: Single replica VLLM serverpostgresql: StatefulSet with persistent storage
Services:
jan-api-gateway: ClusterIP exposing port 8080jan-inference-model: ClusterIP exposing port 8101postgresql: ClusterIP exposing port 5432
Configuration:
- Environment variables via Helm values
- Secrets for sensitive data (JWT keys, OAuth credentials)
- ConfigMaps for application settings
Helm Chart Structure
The system uses Helm charts for deployment configuration:
charts/├── umbrella-chart/ # Main deployment chart that orchestrates all services│ ├── Chart.yaml│ ├── values.yaml # Configuration values for different environments│ └── Chart.lock└── apps-charts/ # Individual service charts ├── jan-api-gateway/ # API Gateway service chart └── jan-inference-model/ # Inference Model service chart
Chart Features:
- Umbrella Chart: Main deployment chart that orchestrates all services
- Service Charts: Individual charts for each service (API Gateway, Inference Model)
- Values Files: Configuration files for different environments
Security Architecture
Authentication Methods
- JWT Tokens: HMAC-SHA256 signed tokens for API access
- OAuth2: Google OAuth2 integration for user login
- API Keys: HMAC-SHA256 signed keys for service access
Network Security
- Internal Communication: Services communicate over Kubernetes cluster network
- External Access: Only API gateway exposed via port forwarding or ingress
- Database Access: PostgreSQL accessible only within cluster
Data Security
- Secrets Management: Kubernetes secrets for sensitive configuration
- Environment Variables: Non-sensitive config via environment variables
- Database Encryption: Standard PostgreSQL encryption at rest
Production deployments should implement additional security measures including TLS termination, network policies, and secret rotation.
Monitoring & Observability
Health Monitoring
- Health Check Endpoints: Available on all services
- Model Health Monitoring: Automated health checks for inference models
- Database Health: Connection monitoring and replica status
Performance Profiling
- pprof Endpoints: Available on port 6060 for performance analysis
- Grafana Pyroscope: Continuous profiling integration
- Request Tracing: Unique request IDs for end-to-end tracing
Logging
- Structured Logging: JSON-formatted logs across all services
- Request/Response Logging: Complete request lifecycle tracking
- Error Tracking: Unique error codes for debugging
Database Monitoring
- Read/Write Replica Support: Automatic load balancing
- Connection Pooling: Optimized database connections
- Migration Tracking: Automatic schema migration monitoring
- Transaction Monitoring: Automatic rollback on errors
Scalability Considerations
Current Limitations:
- Single replica deployments
- No horizontal pod autoscaling
- Local storage for database
Future Enhancements:
- Multi-replica API gateway with load balancing
- Horizontal pod autoscaling based on CPU/memory
- External database with clustering
- Redis caching layer
- Message queue for async processing
Project Structure
jan-server/├── apps/ # Application services│ ├── jan-api-gateway/ # Main API gateway service│ │ ├── application/ # Go application code│ │ ├── docker/ # Docker configuration│ │ └── README.md # Service-specific documentation│ └── jan-inference-model/ # AI model inference service│ ├── application/ # Python application code│ └── Dockerfile # Container configuration├── charts/ # Helm charts│ ├── apps-charts/ # Individual service charts│ └── umbrella-chart/ # Main deployment chart├── scripts/ # Deployment and utility scripts└── README.md # Main documentation
Development Architecture
Building Services
# Build API Gatewaydocker build -t jan-api-gateway:latest ./apps/jan-api-gateway# Build Inference Modeldocker build -t jan-inference-model:latest ./apps/jan-inference-model
Database Migrations
The system uses Atlas for database migrations:
# Generate migration filesgo run ./apps/jan-api-gateway/application/cmd/codegen/dbmigration# Apply migrationsatlas migrate apply --url "your-database-url"
Code Generation
- Swagger: API documentation generated from Go annotations
- Wire: Dependency injection code generated from providers
- GORM Gen: Database model generation from schema
Build Process
- API Gateway: Multi-stage Docker build with Go compilation
- Inference Model: Base VLLM image with model download
- Helm Charts: Dependency management and templating
- Documentation: Auto-generation during development
Local Development
- Hot Reload: Source code changes reflected without full rebuild
- Database Migrations: Automated schema updates
- API Testing: Swagger UI for interactive testing
- Logging: Structured logging with configurable levels